Продолжаем серию статей про поддержку JSON в SQL Server 2016. В этой части мы рассмотрим, как можно хранить и индексировать JSON объекты в базе данных.
Как я уже раньше упоминал, в SQL Server 2016 не был добавлен отдельный тип для JSON, в отличие от XML. Поэтому для его хранения вы можете использовать любые строковые типы данных. Лучше всего, пожалуй, подойдут varchar(max) и nvarchar(max) в зависимости от того, есть ли у вас Unicode символы в JSON документах или нет. Однако, вы можете использовать типы данных с меньше длиной, если вы точно уверены, что ваши JSON объекты не выйдут по размеру за их пределы.
Если кто-то работал с XML, то помнит, что для этого формата в SQL Server существует несколько типов индексов, позволяющих ускорить определенные выборки. Для строковых же типов, в которых предполагается хранение JSON таких индексов просто не существует. Тут нам на помощь приходят вычисляемые столбцы, которые могут представлять из себя определенные свойства из JSON документов, по которым мы хотим производить поиск, а индексы создать уже на этих столбцах.
use test;
go
drop table if exists dbo.test_table;
go
create table dbo.test_table (
id int not null,
json_data varchar(max) null,
constraint pk_test_table primary key clustered (id)
);
go
insert into dbo.test_table (
id,
json_data
)
values
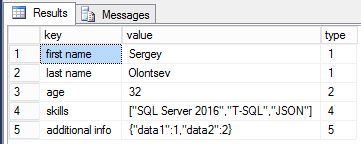
(1, '{"first name":"Sergey","last name":"Olontsev","age":32,"skills":["SQL Server 2016","T-SQL","JSON"]}'),
(2, '{"first name":"John","last name":"Smith","sex":"m","skills":["SQL Server 2014","In-Memory OLTP"]}'),
(3, '{"first name":"Mary","last name":"Brown","age":25,"skills":["SQL Server 2016","In-Memory OLTP"]}');
go
alter table dbo.test_table
add v_age as json_value(json_data, '$.age') persisted;
go
alter table dbo.test_table
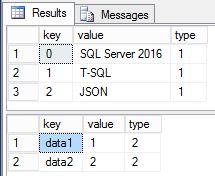
add v_skills as json_query(json_data, '$.skills') persisted;
go
create nonclustered index ix_nc_test_table_v_age on [dbo].[test_table] (v_age);
go
create fulltext catalog [jsonFullTextCatalog] with accent_sensitivity = on authorization [dbo];
go
create fulltext index on [dbo].[test_table] (v_skills)
key index pk_test_table ON jsonFullTextCatalog;
go
select *
from [dbo].[test_table] as t
where
t.[v_age] = 32;
select *
from [dbo].[test_table] as t
where
contains(t.v_skills, 'OLTP');
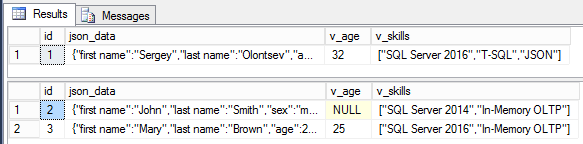
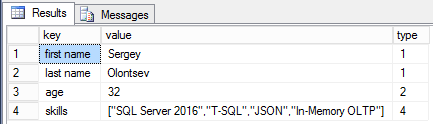
Вычисляемые столбцы лучше создать как persisted, иначе теряется весь смысл в индексировании этих столбцов. Также, можно создавать как обычные индексы, так и полнотекстовые, если мы хотим получить чуть более гибкий поиск по содержимому массивов или целых частей объектов. При этом полнотекстовые индексы не имеют каких-то специальных правил обработки JSON, они всего лишь разбивают текст на отдельные слова используя в качестве разделителей двойные кавычки, запятые, скобки и т.п.
Вот и все, что я хотел рассказать про хранение и индексирование JSON в SQL Server 2016. В следующей части серии я попробую провести сравнение хранения и обработки JSON и XML в SQL Server и выяснить опытным путем, какой же формат лучше использовать для хранения и передачи неструктурированных данных.
 Осталось чуть меньше двух недель до, пожалуй, главного события на юге России, посвященного SQL Server – это, уже ставшая
Осталось чуть меньше двух недель до, пожалуй, главного события на юге России, посвященного SQL Server – это, уже ставшая