Несомненно, правильная или, наоборот, неправильная настройка tempdb может очень сильно повлиять на производительность SQL Server. Эта системная база данных является глобальным ресурсом и доступна всем пользователям, которые подключаются к SQL Server, и предназначена, чтобы хранить следующие данные:
- Временные объекты, созданные пользователями: временные локальные или глобальные таблицы, табличные переменные, временные процедуры и курсоры.
- Внутренние объекты, которые создаются движком SQL Server, например, рабочие таблицы (worktable), которые используются для хранения временных результатов сортировки, а также скрытые буферные таблицы (spool).
- Версии строк, которые генерируются при модификации данных в базе, где используются оптимистичные уровни изоляции.
- Версии строк, которые генерируются при онлайн перестроении индексов, AFTER триггеров или MARS (Multiple Active Result Sets).
Т.е. база tempdb может активно использовать даже запросами, которые явно не создают никаких временных объектов. Я сейчас не планирую описывать все тонкости конфигурации этой базы, а лишь сосредоточусь на тех изменениях, которые появились в SQL Server 2016.
В первую очередь, уже при установке, на одном из этапов нам предлагают выбрать, сколько файлов и какого размера будет создано для tempdb.
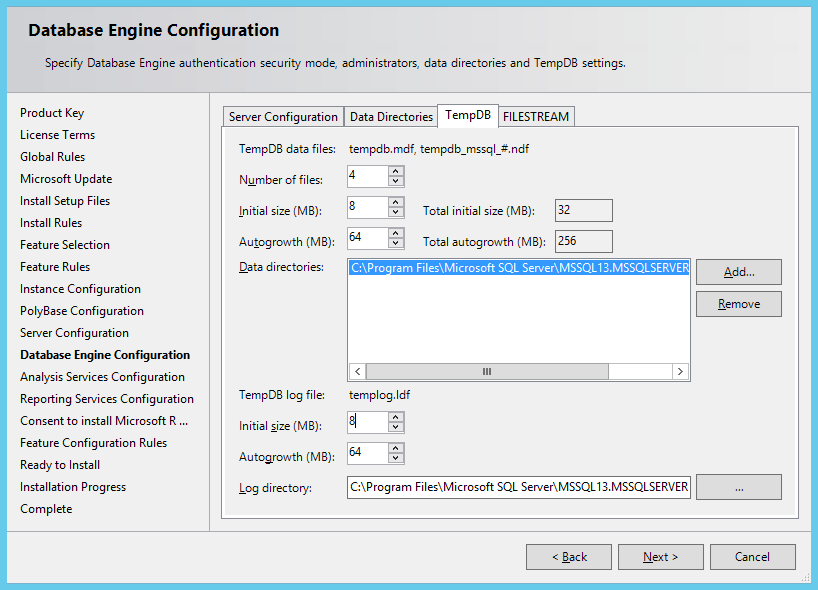
Многие из вас должны быть в курсе, что раньше по умолчанию создавался всего 1 файл данных под tempdb. В ситуациях, когда несколько сессий активно работают с этой системной базой, возникала конкуренция за внутренние ресурсы (contention). Поэтому появилось очень много рекомендаций, сколько же файлов лучше создавать под базу tempdb. По умолчанию инсталлятор руководствуется следующей формулой: минимум из 2х значений, количество ядер на вашей системе и 8. Т.е., если у вас меньше 8 ядер, то будет предложено создать столько файлов, сколько у вас в системе ядер. В остальных случаях будет просто предложено создать 8 файлов, независимо от того, сколько у вас ядер.
| Ядер CPU | Количество файлов в tempdb |
| 2 | 2 |
| 4 | 4 |
| 8 | 8 |
| 32 | 8 |
Возможно, и даже скорее всего, что 8 файлов для многопроцессорных нагруженных серверов будет мало (нет универсальной формулы, которая бы ответила на этот вопрос, нужно смотреть на характер нагрузки на ваш сервер), но по умолчанию это вполне разумные настройки. Создавать файлов больше, чем у вас ядер в системе, не будет иметь практического смыла, ввиду того, что одновременно с tempdb не будет работать больше сессий, чем у вас ядер в системе.
Далее, что еще бросается в глаза. По умолчанию размер файлов составляет 8 Мб и прирост 64 Мб. Опять же, в большинстве случаев эти цифры необходимо будет увеличить в зависимости от ваших потребностей. Хорошо, на мой взгляд, что в инсталляторе отсутствуют параметры прироста в процентах, что практически всегда является плохой практикой.
Еще стоит отметить, что вы можете указать несколько директорий, в которых будут созданы файлы данных. Файлы будут распределены по этим директориям по алгоритму round-robin. Например, вы указали создать 8 файлов данных и разместить их в 3х директориях. В этом случае установщик расположит их следующим образом:
| Файл данных | Директория |
| tempdb.mdf | 1 |
| tempdb_mssql_2.ndf | 2 |
| tempdb_mssql_3.ndf | 3 |
| tempdb_mssql_4.ndf | 1 |
| tempdb_mssql_5.ndf | 2 |
| tempdb_mssql_6.ndf | 3 |
| tempdb_mssql_7.ndf | 1 |
| tempdb_mssql_8.ndf | 2 |
Улучшения в производительности при работе с tempdb
Также в работу tempdb были внесены следующие изменения, направленные на оптимизацию и ускорение выполнения запросов:
- Кэширование временных объектов позволяет запросам, которые постоянно удаляют и создают временные объекты работать быстрее и уменьшают конкуренцию за системные ресурсы. В последних версиях SQL Server можно было регулярно видеть изменения и улучшения этого механизма.
- Уменьшена нагрузка на журнал транзакций в tempdb, снижено количество требуемых I\O операций.
- Доработан алгоритм накладывания latch’ей при выделении страниц, уменьшено их количество.
- При приращении tempdb теперь одновременно будет увеличен размер всех файлов (отпадает необходимость включать флаг трассировки 1117). Опция AUTOGROW_ALL_FILES включена по умолчанию и не может быть изменена. Это поможет избежать разбалансирования размеров файлов при постоянно приросте tempdb.
- Для временных объектов идет выделение только экстентами (блоками по 8 страниц, 64 кб). Отпадает необходимость включать флаг трассировки 1118. Это также поможет в большей части случаев.
Как мы можем видеть, в этом релизе сделали довольно большой шаг к исправлению откровенно плохих настроек tempdb по умолчанию. Конечно, придется еще самостоятельно выбирать больше 8 файлов, если вам они действительно нужны, а также их размер и прирост, но, в остальном, я только приветствую эти изменения.



 В последнюю пятницу июля традиционно отмечают
В последнюю пятницу июля традиционно отмечают