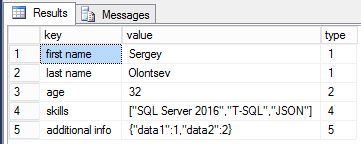
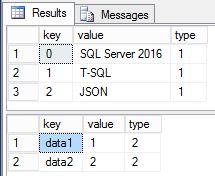
Свершилось! Наконец-то в SQL Server 2016 появляется встроенная функция для разбивки строк. Пожалуй, это одна из самых распространённых функций, которые, пожалуй, присутствуют на каждом SQL Server, но до текущей версии были реализованы своими силами. Это та функция, для которой существует множество самых различных реализаций, и, зачастую, не самых быстрых. Давайте поближе взглянем на возможности функции STRING_SPLIT, ее ограничения и сравним ее по скорости с самыми распространенными решениями.
Функция принимает всего 2 параметра: собственно, саму строку, которую необходимо разбить и разделитель. Существует одно очень важное и не очень понятное ограничение, разделитель может быть только длиной один символ. Поэтому, если вам требуется разбить строку по большему разделителю, то эта функция для вас не подойдет, и вам нужно искать другое решение.
На текущий момент одним из самых быстрых решений по разбивки строк считается CLR функция, написанная Adam Machanic (ссылка на статью). Также я решил привести пару других примеров функции, реализация в лоб, а также через inline функцию с соединением с таблицей чисел. Последний из этих вариантов на строках небольшой длины обычно показывает неплохие результаты по сравнению с реализацией в лоб. Ну и сравним скорость со стандартной функцией, входящей в SQL Server 2016. Для начала подготовим таблицу с числами и добавим 2 вышеуказанные функции. Как скомпилировать и добавить CLR функцию, я не привожу, т.к. надеюсь, каждый сможет это сделать самостоятельно.
use test;
go
if object_id('dbo.num', 'U') is not null
drop table dbo.num;
go
create table dbo.num (
n int primary key clustered
);
go
insert into dbo.num(n)
select top (1000000) row_number() over (order by (select 1)) as rn
from sys.all_columns as t1
cross apply sys.all_columns as t2
go
if object_id('dbo.fn_split', N'TF') is not null
drop function dbo.fn_split;
go
create function dbo.fn_split
(
@str nvarchar(max),
@del nchar(1)
)
returns @returntable table
(
st nvarchar(4000)
)
as
begin
while charindex(@del, @str) > 0
begin
insert into @returntable select substring(@str, 1, charindex(@del, @str) - 1)
set @str = substring(@str, charindex(@del, @str) + 1, len(@str))
end
if @str <> ''
insert into @returntable values(@str)
return
end
go
if object_id('dbo.fn_split2', 'if') is not null
drop function dbo.fn_split2;
go
create function dbo.fn_split2 (
@str nvarchar(max),
@del nchar(1) = ','
) returns table
as
return
select
substring(@str, n, case when charindex(@del, @str, n) = 0 then len(@str) else charindex(@del, @str, n) - n end) as st
from dbo.num
where
n <= len(@str)
and (n = 1 or substring(@str, n - 1, 1) = @del)
go
И, собственно, сам код для теста, в котором я сначала подготавливаю текст из 20 тысяч слов разделенных запятой, а потом проверяю его разбивку различными методами.
set statistics time on
declare @str varchar(max) = (select top (20000) t1.name + ',' as 'text()'
from sys.all_columns as t1
cross apply sys.all_columns as t2
for xml path(''))
set @str = substring(@str, 1, len(@str) - 1)
select *
from dbo.split_string_clr(@str, ',');
select *
from dbo.fn_split(@str, ',') as f;
select *
from dbo.fn_split2(@str, ',') as f;
select *
from string_split(@str, ',');
Ну и приведу один из полученных результатов.
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 113 ms.
SQL Server Execution Times:
CPU time = 13468 ms, elapsed time = 13759 ms.
SQL Server Execution Times:
CPU time = 143875 ms, elapsed time = 143989 ms.
SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 216 ms.
Как мы видим, CLR функция и STRING_SPLIT оставляют далеко позади остальные решения, а вот выбрать, кто из них быстрее становится проблематично, т.к. их время запуска практически не отличается и варьируется от теста к тесту. В данном случае расходы на CPU одинаковые, а время выполнения медленнее. Однако, в каких-то запусках, время выполнения становится сравнимым, поэтому я не берусь отдать пальму первенства ни одной из них. Это действительно круто, что наконец-то появляется встроенное решение с превосходной производительностью. Но, если вам потребуется использовать разделитель больше чем в один символ, то рекомендую пользоваться CLR решением.
 Осталось чуть меньше двух недель до, пожалуй, главного события на юге России, посвященного SQL Server – это, уже ставшая
Осталось чуть меньше двух недель до, пожалуй, главного события на юге России, посвященного SQL Server – это, уже ставшая