В SQL Server в языке T-SQL имеется два оператора SET и SELECT, и они оба могут использоваться для присваивания значений переменным. В некоторых ситуациях использование того или иного оператора может привести к неожиданным и непредсказуемым результатам. В этой статье я бы хотел подробно рассмотреть различия между ними и рассказать о различных ловушках, в которые вы можете попасть.
В первую очередь, оба оператора могут равнозначно использоваться для присваивания фиксированных значений переменных. Однако, оператор SET является стандартом для языка SQL, в то время как SELECT является особенностью только T-SQL диалекта в SQL Server.
declare
@int_example int,
@dt_example datetime,
@str_example varchar(255);
set @int_example = 1;
set @dt_example = getdate();
set @str_example = 'qwe';
select @int_example, @dt_example, @str_example;
select @int_example = 1;
select @dt_example = getdate();
select @str_example = 'qwe';
select @int_example, @dt_example, @str_example;
go
Однако, если мы хотим за одну операцию инициализировать сразу несколько переменных, то необходимо использовать оператор SELECT.
declare
@int_example int,
@dt_example datetime,
@str_example varchar(255);
select
@int_example = 1,
@dt_example = getdate(),
@str_example = 'qwe';
select @int_example, @dt_example, @str_example;
go
Если же мы попытаемся использовать в данной ситуации SET, то получим ошибку, т.к. он просто не поддерживает такую операцию.
declare
@int_example int,
@dt_example datetime,
@str_example varchar(255);
set
@int_example = 1,
@dt_example = getdate(),
@str_example = 'qwe';
select @int_example, @dt_example, @str_example;
go
Msg 102, Level 15, State 1, Line 7
Incorrect syntax near ‘,’.
Также оба оператора могут применяться для присваивания значений переменным из таблицы. Однако, если SELECT можно использовать напрямую, то в случае с SET придется все равно использовать SELECT, чтобы получить выборку из таблицы, и уже пытаться ее результаты присвоить переменной.
create table #tmp (
id int not null,
int_example int not null,
dt_example datetime not null,
str_example varchar(255) not null
);
insert into #tmp (
id,
int_example,
dt_example,
str_example
)
values
(1, 1, '19000101', 'qwe'),
(2, 2, '19020101', 'qwe2'),
(3, 31, '19030101', 'qwe31'),
(3, 32, '19030202', 'qwe32');
declare
@int_example int,
@dt_example datetime,
@str_example varchar(255);
set @int_example = (select int_example from #tmp where id = 1);
select @int_example;
select @int_example = int_example from #tmp where id = 2;
select @int_example;
go
Единственное, необходимо учитывать, что, если результат запроса к таблице вернет больше одного значения, то в случае с операцией SET мы получим ошибку.
create table #tmp (
id int not null,
int_example int not null,
dt_example datetime not null,
str_example varchar(255) not null
);
insert into #tmp (
id,
int_example,
dt_example,
str_example
)
values
(1, 1, '19000101', 'qwe'),
(2, 2, '19020101', 'qwe2'),
(3, 31, '19030101', 'qwe31'),
(3, 32, '19030202', 'qwe32');
declare
@int_example int,
@dt_example datetime,
@str_example varchar(255);
set @int_example = (select int_example from #tmp where id = 3);
select @int_example;
go
Msg 512, Level 16, State 1, Line 25
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.
В случае же использования оператора SELECT ошибки не возникнет, но в общем случае мы не можем точно предугадать, какое из удовлетворяющих условию выборки значений будет присвоено переменной. Рассмотрим первый случай, в котором запрос вернет 32.
create table #tmp (
id int not null,
int_example int not null,
dt_example datetime not null,
str_example varchar(255) not null
);
insert into #tmp (
id,
int_example,
dt_example,
str_example
)
values
(1, 1, '19000101', 'qwe'),
(2, 2, '19020101', 'qwe2'),
(3, 31, '19030101', 'qwe31'),
(3, 32, '19030202', 'qwe32');
declare
@int_example int,
@dt_example datetime,
@str_example varchar(255);
select @int_example = int_example from #tmp where id = 3;
select @int_example;
go
В следующем случае запрос возвращает 31.
create table #tmp (
id int not null,
int_example int not null,
dt_example datetime not null,
str_example varchar(255) not null
);
insert into #tmp (
id,
int_example,
dt_example,
str_example
)
values
(1, 1, '19000101', 'qwe'),
(2, 2, '19020101', 'qwe2'),
(3, 32, '19030202', 'qwe32'),
(3, 31, '19030101', 'qwe31');
declare
@int_example int,
@dt_example datetime,
@str_example varchar(255);
select @int_example = int_example from #tmp where id = 3;
select @int_example;
go
Как мы сумели убедиться, недетерминированность выборки может приводить к неожиданным результатам. Поэтому в данном случае я бы рекомендовал использовать оператор SET, чтобы как минимум получить ошибку, а также следить за условиями выборки, чтобы не допускать подобных ситуаций.
И еще один момент, на котором я бы хотел остановиться, когда под условия выборки не попадает ни одной записи и при этом значение переменной уже инициализировано каким-либо значением.
create table #tmp (
id int not null,
int_example int not null,
dt_example datetime not null,
str_example varchar(255) not null
);
insert into #tmp (
id,
int_example,
dt_example,
str_example
)
values
(1, 1, '19000101', 'qwe'),
(2, 2, '19020101', 'qwe2'),
(3, 31, '19030101', 'qwe31'),
(3, 32, '19030202', 'qwe32');
declare
@int_example int,
@dt_example datetime,
@str_example varchar(255);
set @int_example = 5;
set @int_example = (select int_example from #tmp where id = 4);
select @int_example;
set @int_example = 5;
select @int_example = int_example from #tmp where id = 4;
select @int_example;
go
Как мы можем легко убедиться, оператор SET присвоил значению переменной NULL, а вот оператор SELECT просто проигнорировал присваивание и оставил значение переменной таким, каким оно было этой попытки. В результате, если мы будем использовать оператор SELECT, мы не можем точно знать, было ли проинициализировано значение переменной или нет. Как вариант мы можем проверять значение переменной @@rowcount, которое будет равно нулю, если оператор SELECT не нашел ни одной записи, подходящей под условие и инициализации не произошло.
create table #tmp (
id int not null,
int_example int not null,
dt_example datetime not null,
str_example varchar(255) not null
);
insert into #tmp (
id,
int_example,
dt_example,
str_example
)
values
(1, 1, '19000101', 'qwe'),
(2, 2, '19020101', 'qwe2'),
(3, 31, '19030101', 'qwe31'),
(3, 32, '19030202', 'qwe32');
declare
@int_example int,
@dt_example datetime,
@str_example varchar(255);
set @int_example = 5;
set @int_example = (select int_example from #tmp where id = 4);
select @@rowcount;
select @int_example;
set @int_example = 5;
select @int_example = int_example from #tmp where id = 4;
select @@rowcount;
select @int_example;
go
Подведем итоги, вы можете использовать оба оператора, но должны четко понимать, в какой ситуации и что от них ожидать.
Используйте оператор SET, если:
- Если вы присваиваете фиксированные значения переменным без использования запросов и хотите следовать стандартам.
- Ожидаете, что переменной будет присвоено значение NULL, если запрос не вернул никаких результатов.
- Запрос может вернуть несколько значений, и вы хотите отслеживать такие ситуации.
И используйте оператор SELECT, если:
- Хотите за одну инструкцию присвоить значения сразу нескольким переменным.
- В случае выборки значения из таблицы готовы контролировать, действительно ли произошла инициализация, например, с помощью @@rowcount.


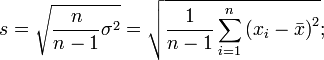
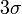 ), которое утверждает, что практически все значения выборки будут лежать в диапазоне 3х сигм от среднего.
), которое утверждает, что практически все значения выборки будут лежать в диапазоне 3х сигм от среднего.
