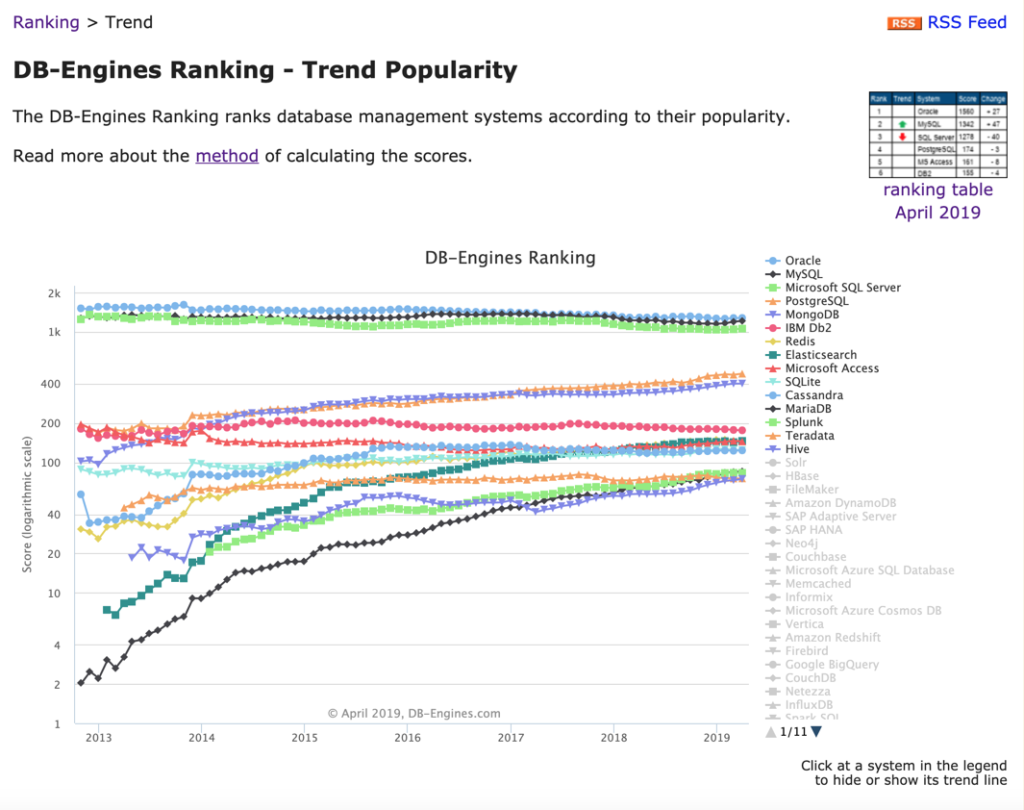
Т.к. T-SQL и R разные языки, каждый со своими типами данных, то сразу возникает много вопросов о совместимости между ними. R поддерживает только ограниченный набор типов: numeric, integer, complex, logical, character, date/time и raw. Все типы T-SQL будут неявно преобразованы в их соответствующие аналоги в R. Однаго, следующие типы данных T-SQL не поддерживаются в R.
- cursor
- timestamp
- datetime2, datetimeoffset, time
- sql_variant
- text, ntext, image
- xml
- CLR типы данных (в т.ч. hierarchyid, geometry, geography)
- binary, varbinary (но могут передаваться как параметры)
Поэтому при попытке передать значения этих типов вы получите ошибку.
execute sp_execute_external_script
@language = N'R',
@script = N'OutputDataSet <- InputDataSet;',
@input_data_1 = N'select cast(''19000101'' as sql_variant);'
with result sets undefined;
go
Msg 39017, Level 16, State 1, Line 74
Input data query returns column #0 of type 'sql_variant' which is not supported by the runtime for 'R' script. Unsupported types are binary, varbinary, timestamp, datetime2, datetimeoffset, time, nchar, nvarchar, ntext, image, hierarchyid, xml, sql_variant and user-defined type.
Сейчас в документации типы nvarchar и nchar также отображаются как неподдерживаемые, и в RC версиях попытка передать их действительно вызывала ошибку, однако в RTM они уже полностью поддерживаются. Просто документацию еще не успели обновить, это должно произойти в ближайшее время.
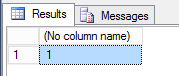
Если вы хотите посмотреть, какие типы данных T-SQL в какие типы данных R будут конфертированы, то для этого можно воспользоваться функцией str в R.
execute sp_execute_external_script
@language = N'R',
@script = N'str(InputDataSet);',
@input_data_1 = N'select cast(''20000101'' as datetime) as v1, cast(1 as int) as v2, cast(1 as bit) as v3, cast(''qwe'' as varchar(100)) as v4, cast(1.01 as numeric(5, 2)) as v5;'
with result sets none;
go
STDOUT message(s) from external script:
'data.frame': 1 obs. of 5 variables:
$ v1: POSIXct, format: "2000-01-01"
$ v2: int 1
$ v3: logi TRUE
$ v4: Factor w/ 1 level "qwe": 1
$ v5: num 1.01
Отдельно стоит отметить binary типы данных. Вы не сможете передать и получить бинарные данные через набор, однако это можно сделать через переменные. Следующий запрос вернет ошибку.
execute sp_execute_external_script
@language = N'R',
@script = N'OutputDataSet <- InputDataSet;',
@input_data_1 = N'select cast(0x01 as binary(1));'
with result sets undefined;
go
Msg 39017, Level 16, State 1, Line 74
Input data query returns column #0 of type 'binary(1)' which is not supported by the runtime for 'R' script. Unsupported types are binary, varbinary, timestamp, datetime2, datetimeoffset, time, nchar, nvarchar, ntext, image, hierarchyid, xml, sql_variant and user-defined type.
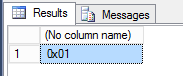
Однако через переменные все отработает успешно.
declare @in_v binary(1) = 0x01, @out_v binary(1);
execute sp_execute_external_script
@language = N'R',
@script = N'out_v1 <- in_v1;',
@params = N'@in_v1 binary(1), @out_v1 binary(1) output',
@in_v1 = @in_v,
@out_v1 = @out_v output
with result sets none;
select @out_v;
go
Также R содержит несколько специальных значений, таких как +Inf, -Inf, NaN и NA. Все они при передаче в T-SQL будут конвертированы в NULL.
execute sp_execute_external_script
@language = N'R',
@script = N'OutputDataSet <- data.frame(v1 = +Inf, v2 = -Inf, v3 = NaN, v4 = NA, v5 = 1);'
with result sets undefined;
go

И еще один очень важный момент, который тоже надо учитывать. Даже поддерживаемые и совместимые типы данных имеют разный допустимый диапазон значений. Например, datetime в T-SQL может принимать более широкий диапазазон значений, чем дата и время в R. Поэтому все недопустимые значения будут неявно конвертированы в NULL. При этом вы не получите никаких ошибок. Поэтому нужно быть очень аккуратным и учитывать этот факт.
execute sp_execute_external_script
@language = N'R',
@script = N'OutputDataSet <- InputDataSet;',
@input_data_1 = N'select cast(''19000101'' as datetime) as v1, cast(''20000101'' as datetime) as v2, cast(''19700101'' as datetime) as v3;'
with result sets undefined;
go

execute sp_execute_external_script
@language = N'R',
@script = N'str(InputDataSet);',
@input_data_1 = N'select cast(''19000101'' as datetime) as v1, cast(''20000101'' as datetime) as v2, cast(''19700101'' as datetime) as v3;'
with result sets none;
go
STDOUT message(s) from external script:
'data.frame': 1 obs. of 3 variables:
$ v1: POSIXct, format: NA
$ v2: POSIXct, format: "2000-01-01"
$ v3: POSIXct, format: "1970-01-01"
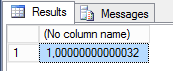
Кроме того стоит учитывать тот факт, что точность при передаче дробных значений также может теряться.
execute sp_execute_external_script
@language = N'R',
@script = N'OutputDataSet <- InputDataSet;',
@input_data_1 = N'select cast(1.000000000000321 as numeric(28, 20)) as v1;'
with result sets undefined;
go
На этом пока все про особенности поддержки различных типов данных. Это довольно важная тема с некоторыми особенностями. В следующей статье мы рассмотрим обработку больших наборов данных, рассмотрим параллелизм и его особенности.