Мы знаем, что Enterprise редакция SQL Server содержит некоторые улучшения, которые при определенных условиях позволяют выполнять операции более оптимально, чем в Standard редакции. Одной из таких вещей является Advanced Scanning, которая позволяет нескольким запросам на сканирование делить одну операцию физического чтения с диска. Также можно встретить другое название этой особенности: Merry-go-Round Scan.
Например, у нас есть большая таблица Table1 состоящая из 1 000 000 страниц. Пользователь UserA начинает выполнять инструкцию T-SQL, которая требует сканирования таблицы. В тот момент, когда выполнилось сканирование 200 000 страниц пользователь UserB подключается и начинает другой запрос, который также требует сканирование Table1. Для сканирования после 200 001-ой страницы компонент Database Engine запланирует всего одно физическое чтение и будет возвращать полученные строки обоим планам выполнения. После сканирования 500 000 страниц пользователь UserC подключается и также запрашивает все данные из таблицы Table1. Теперь операция физического сканирования уже делится между 3мя запросами. Как только сканирование закончится для пользователя UserA, оно продолжится для пользователей UserB и UserC, но уже с 1-ой страницы и соответственно до 200 000 для UserB и до 500 000 для UserC.
В чем смысл этой оптимизации. Если у вас имеются очень большие таблицы, которые не вмещаются целиком в оперативную память и их сканирование приводит к «вымыванию» буферного пула и такие сканирования идут часто и параллельно, то такая оптимизация поможет снизить давление на буферный пул и не делать сканирование несколько раз.
Для демонстрации давайте создадим достаточно большую таблицу с кластеризованным индексом в БД AdventureWorks2012.
use
[AdventureWorks2012];
go
select
[DatabaseLogID],
[PostTime],
[DatabaseUser],
[Event],
[Schema],
[Object],
[TSQL],
[XmlEvent]
into [dbo].[BigDatabaseLog]
from [dbo].[DatabaseLog];
go
insert into [dbo].[BigDatabaseLog]
(
[PostTime],
[DatabaseUser],
[Event],
[Schema],
[Object],
[TSQL],
[XmlEvent]
)
select
[PostTime],
[DatabaseUser],
[Event],
[Schema],
[Object],
[TSQL],
[XmlEvent]
from [dbo].[DatabaseLog];
go 200
create clustered index [IX_CL_DatabaseLogID]
on [dbo].[BigDatabaseLog]
(
[DatabaseLogID] asc
) on [PRIMARY];
go
Также стоит отметить, что Advanced Scanning работает только в том случае, если нет требования, чтобы поток данных был отсортирован. Например, как в следующем плане запроса:
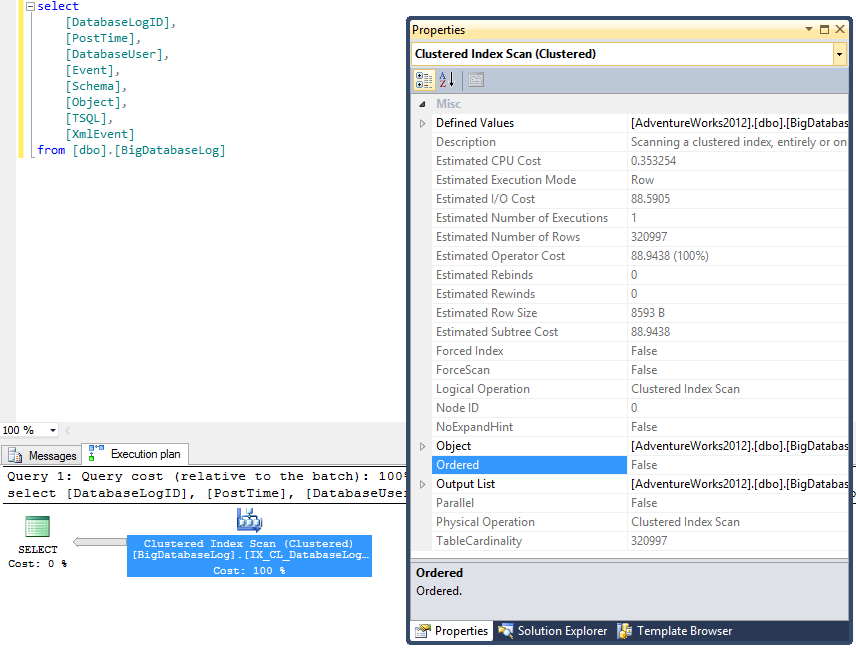
Данная оптимизация является ярким подтверждением того, что сканирование кластеризованного индекса без требования к сортировке может привести к выдаче данных, которые будут не отсортированы. И действительно, если я начну запускать указанный запрос в нескольких сессиях с паузой между запусками, я буду получать результаты без гарантии сортировки.
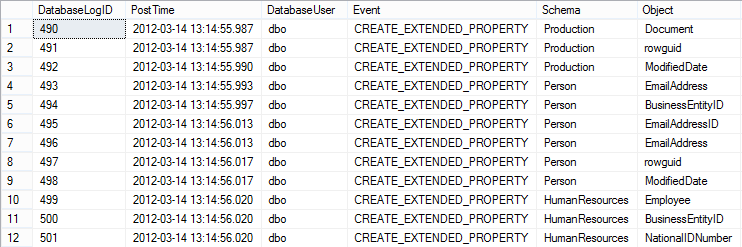
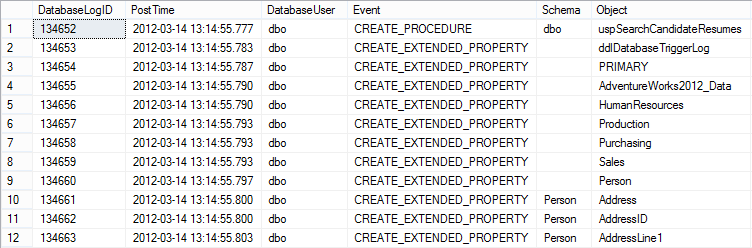
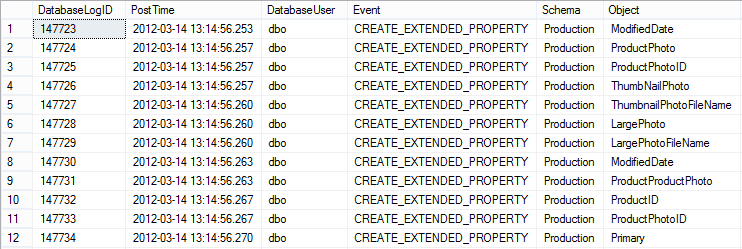
Дополнительно стоит отметить, что у меня получилось провести указанный эксперимент только для сканирования кластеризованного индекса, который целиком не помещается в буферный пул. Я ограничивал размер максимальной памяти в SQL Server 400 мегабайтами. В двух следующих ситуациях вышеуказанное НЕ работало:
- При сканировании heap таблицы (без кластеризованного индекса) данные всегда возвращались в одном порядке.
- Также, если таблица целиком закэширована в буферном пуле, результаты также возвращались в одном порядке, но это ничему не противоречит, т.к. тяжелых операций чтения с диска при этом нет, а только логические чтения из буферного пула.