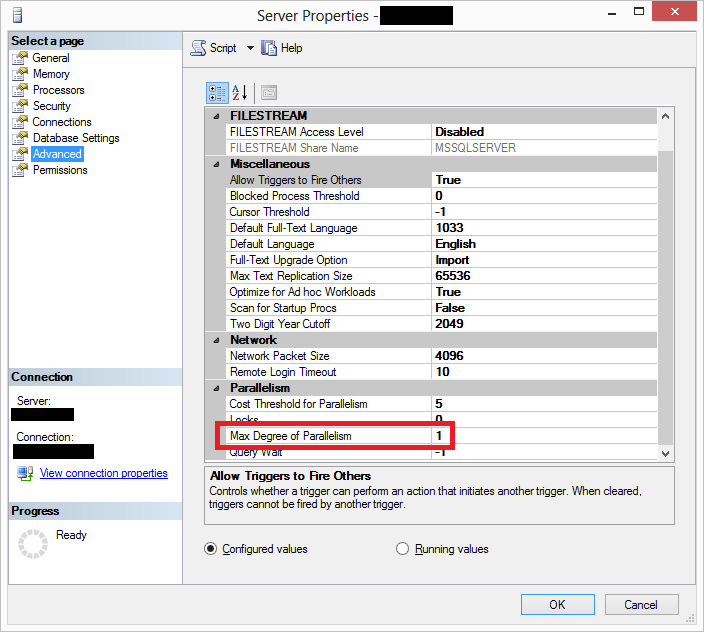
В этой небольшой заметке я бы хотел немного рассказать о тонкостях в настройках параллелизма в Microsoft SQL Server. Очень многим из вас давно известна опция Max Degree od Parallelism, которая присутствует в SQL Server уже очень давно. По умолчанию она выставлена в 0, что значит, что SQL Server будет сам выбирать оптимальную степень параллелизма, то есть количество процессоров\потоков, задействованных для выполнения одной инструкции. Я сейчас не буду останавливаться и рассуждать, в какое же именно значении лучше выставлять эту опцию – это тема для отдельное заметки. Я лишь рассмотрю, как значение этой опции влияет на выполнение запросов. Например, ниже на рисунке, эта опция выставлена в 1, что означет, что параллельные планы для всех запросов по умолчанию отключены.
Также данная опция доступна для просмотра с помощью следующей команды T-SQL:

И действительно, любой план запроса по умолчанию будет последовательным. Например:

Однако, у разработчика и любого пользователя по-прежнему остается возможность повлиять на это путем использования подсказок (hints). Для этого всего лишь нужно указать нужную степень параллелизма, и генерируется нужный план запроса, например:

И если мы понаблюдаем на этот запрос через представление sys.dm_exec_query_profiles, то увидим, что он действительно выполняется в 10 потоков.
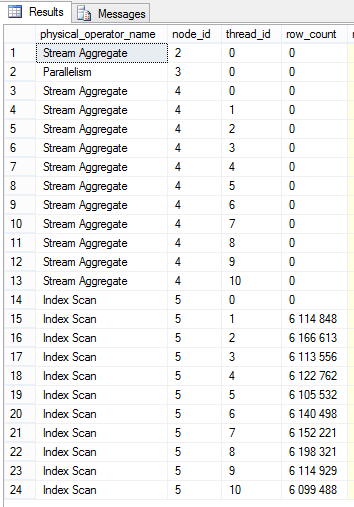
Таким образом, в системе остается потайной лаз, который могут использовать разработчики и пользователи, чтобы «ускорить» (тут я специально поставил в кавычки, т.к. не всегда большая степень параллелизма ведет к уменьшению времени выполнения запроса) свои запросы путем увеличения степени параллелизма. Но, таким образом, они могут просто «убить» сервер, запуская множество неконтролируемых параллельных запросов одновременно. Что же мы можем с этим сделать? Вот тут нам на помощь приходит Resource Governor, очень мощная и совершенно недооцененная система, которая позволяет очень гибко распределить ресурсы между разными группами пользователей. Опять же, я сейчас не буду останавливаться на том, как он устроен, и какими возможностями обладает. Я лишь остановлюсь подробно, как влияют его настройки ограничения параллелизма. Давайте для начала взглянем в настройки по умолчанию:
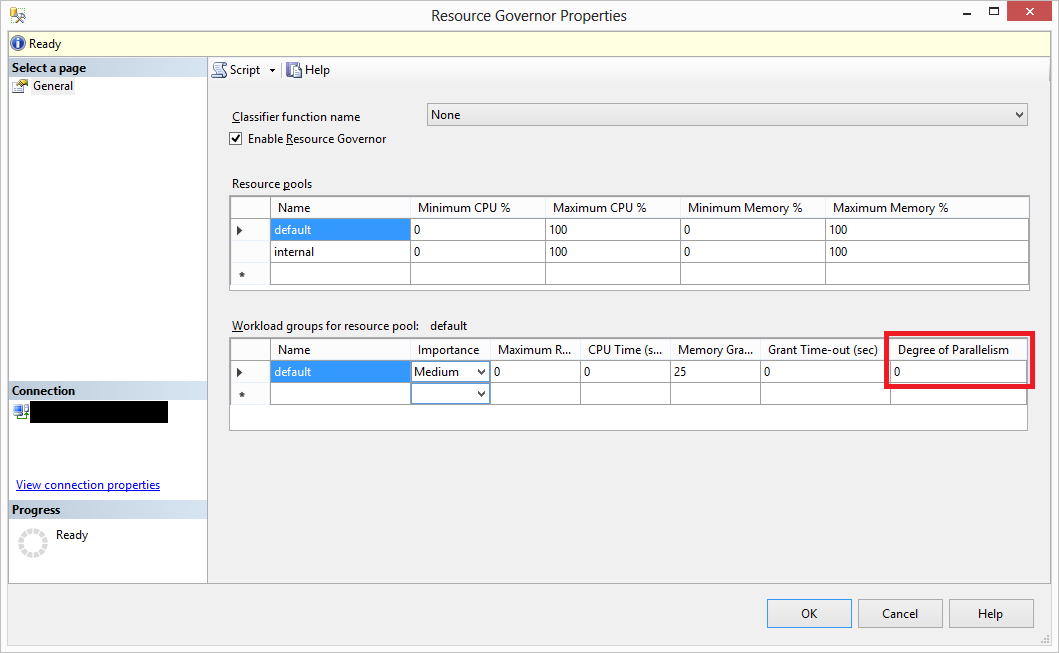
Опять мы видим, что по умолчанию опция выставлена в 0 и решение о выборе максимальной степени отдано на откуп SQL Server. Теперь посмотрим, что будет, если я поменяю это значение в 5. Внимание, ни в коем случае не делайте такие настройки на реальной системе, т.к. я даже не определил функцию классификации для Resource Governor и меняю default группу. Но для теста и понимания, как все работает конкретно сейчас на моем примере, этого хватит. Таким образом, я ограничиваю для всех максимальную степень параллелизма 5 потоками. Напомню, что опция Max Degree of Parallelism, которую мы рассматривали ранее выставлена по-прежнему в значение 1. Если мы теперь посмотрим на план выполнения нашего изначального запроса, то по умолчанию он будет последовательный, а с опцией maxdop 10 – параллельный. Но, если мы запустим параллельный план, то увидим кое-что интересное.
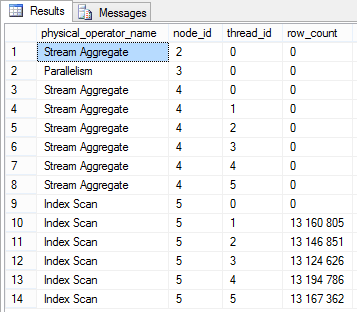
Теперь наш запрос выполняется только в 5 потоков, несмотря на то, что опция maxdop для него имеет значение 10. И, если вы укажете для запроса опцию maxdop 4, он будет выполняться в 4 потока (опция в Resource Governor установлена в 5). В этом случае подсказка maxdop меньше настройки Resource Governor, поэтому дополнительного ограничения не накладывается. Пример этого я уже не привожу.
Таким образом, Resource Governor является более мощным средством, который уже реально ограничивает максимальную степень параллелизма для запросов, и эту степень можно задать разную для разных групп пользователей. При этом опция Max Degree of Parallelism по-прежнему продолжает работать и вносит свою лепту (или слегка запутывает администраторов, разработчиков и пользователей, когда работает в купе с Resource Governor). Далее, лишь только вашей фантазией ограничены варианты выставления значений этих 2х параметров, но важно помнить лишь две вещи: Max Degree of Parallelism и подсказка (hint) maxdop для запроса влияет на то, какой план будет сгенерирован, сколько максимальное количество потоков будет возможно для этого запроса, а Resource Governor еще дополнительно сверху ограничивает запрос уже во время выполнения.
 В последнюю пятницу июля традиционно отмечают
В последнюю пятницу июля традиционно отмечают