Мы подошли, пожалуй, к самой интересной части серии статей про работу с JSON в SQL Server 2016. Я уже упоминал, что разработчики полюбили JSON за его ясную и понятную глазу структуру, а также за меньший размер данных, чем XML. Осталось проверить самое главное, работает ли SQL Server с JSON быстрее, чем с XML. Для этого я написал небольшой тест на замер скорости работы функции JSON_VALUE и метода value() у типа XML. Для JSON я решил проверить, как работает извлечение данных как из типа varchar(max), так и из nvarchar(max). Я составил похожие по структуре JSON и XML и попробую выбирать из них разные типы данных, числовой и строковый и из разных частей документов. Ну и давайте посмотрим, что же получилось.
declare @json varchar(max) = '[
{"first name":"Sergey","last name":"Olontsev","age":32,"skills":["SQL Server 2016","T-SQL","JSON"]},
{"first name":"John","last name":"Smith","sex":"m","skills":["SQL Server 2014","In-Memory OLTP"]},
{"first name":"Mary","last name":"Brown","age":25,"skills":["SQL Server 2016","In-Memory OLTP"]}]';
declare @json_u nvarchar(max) = N'[
{"first name":"Sergey","last name":"Olontsev","age":32,"skills":["SQL Server 2016","T-SQL","JSON"]},
{"first name":"John","last name":"Smith","sex":"m","skills":["SQL Server 2014","In-Memory OLTP"]},
{"first name":"Mary","last name":"Brown","age":25,"skills":["SQL Server 2016","In-Memory OLTP"]}]';
declare @xml xml = N'
32SQL Server 2016T-SQLJSON
mSQL Server 2014In-Memory OLTP
25SQL Server 2016In-Memory OLTP
';
declare
@i int,
@v1 int,
@v2 varchar(100),
@start_time datetime,
@end_time datetime,
@iterations int = 1000000,
@path_expression nvarchar(1000),
@returned_type varchar(100);
declare @results table (
data_type varchar(100) not null,
test_id tinyint not null,
path_expression varchar(1000) not null,
returned_type varchar(1000),
elapsed_time_ms int not null
);
set @returned_type = 'int';
set @path_expression = '$[0].age'
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v1 = json_value(@json, '$[0].age');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'json', 1, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
set @returned_type = 'varchar';
set @path_expression = '$[2]."first name"';
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v2 = json_value(@json, '$[2]."first name"');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'json', 2, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
set @returned_type = 'varchar';
set @path_expression = '$[2].skills[0]';
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v2 = json_value(@json, '$[2].skills[0]');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'json', 3, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
set @returned_type = 'int';
set @path_expression = '$[0].age'
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v1 = json_value(@json_u, '$[0].age');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'json u', 1, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
set @returned_type = 'varchar';
set @path_expression = '$[2]."first name"';
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v2 = json_value(@json_u, '$[2]."first name"');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'json u', 2, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
set @returned_type = 'varchar';
set @path_expression = '$[2].skills[0]';
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v2 = json_value(@json_u, '$[2].skills[0]');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'json u', 3, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
set @returned_type = 'int';
set @path_expression = '(/root/rec/age)[1]';
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v1 = @xml.value('(/root/rec/age)[1]', 'int');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'xml', 1, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
set @returned_type = 'varchar';
set @path_expression = '(/root/rec/@first_name)[3]';
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v2 = @xml.value('(/root/rec/@first_name)[3]', 'varchar(100)');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'xml', 2, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
set @returned_type = 'varchar';
set @path_expression = '/root[1]/rec[3]/skills[1]/skill[1]';
set @i = 1;
set @start_time = getutcdate();
while @i <= @iterations
begin
select @v2 = @xml.value('/root[1]/rec[3]/skills[1]/skill[1]', 'varchar(100)');
set @i += 1;
end
set @end_time = getutcdate();
insert into @results (data_type, test_id, path_expression, returned_type, elapsed_time_ms)
select 'xml', 3, @path_expression, @returned_type, datediff(ms, @start_time, @end_time);
select *
from @results;
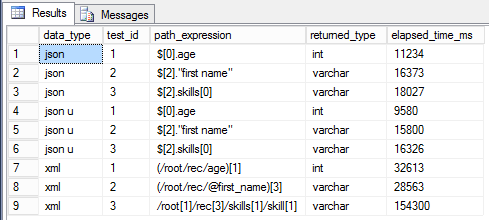
Результаты, если честно, удивили меня самого. В первую очередь стоит отметить, что выбор данных из JSON, хранящегося в типе nvarchar(max), проиходит быстрее на 5-15%, чем из обычного типа без поддержки Unicode. Хотя, должно было бы быть наоборот, т.к. этот тип занимает в 2 раза больше. Но результаты теста опровергают догадки. Выходит, что выгоднее обрабатывать JSON, который хранится в unicode формате. С чем это связано, мне пока не ясно. Ну и, что особенно радует, извлечение данных из JSON происходит от 2-3 до почти 10 раз быстрее, чем из XML. Поэтому можно смело рекомендовать использовать JSON вместо XML там, где это возможно.